Welcome!
Course format and scheduling
Lectures: There is a two-hour lecture each week during the term on Wednesdays from 13:00 to 15:00 in CLM.2.02.
Seminars: There is a one-hour “lab-style” seminar each week during the term. See the LSE Timetable for the schedule and locations for the seminars.
There are no lectures or seminars during week 6, which is LSE’s reading week.
Important course links
Instructors
Office hour slots with all instructors should be booked via LSE’s StudentHub.
- Ryan Hübert, Department of Methodology. Course convenor.
- Dan de Kadt, Department of Methodology.
- Charlotte Kuberka, Department of Government.
Assessments
| Type | Due date | |
|---|---|---|
| 1 | Formative in-class exercises | during seminars |
| 2 | Formative practice problem set | Friday, 1 November 2024, 5pm |
| 3 | Summative mid-term problem set | Friday, 22 November 2024, 5pm |
| 4 | Summative final take-home assessment | Wednesday, 15 January 2025, 5pm |
Outline of topics
Important note: There may be some small changes to and/or reorganisation of the course topics during the first weeks of the course.
| Week | Topic | Lecturer |
|---|---|---|
| 1 | Introduction | Ryan Hübert |
| 2 | Tabular data | Ryan Hübert |
| 3 | Data visualisation | Ryan Hübert |
| 4 | Textual data | Ryan Hübert |
| 5 | HTML, CSS, and scraping static pages | Ryan Hübert |
| 6 | Reading week | |
| 7 | XML, RSS, and scraping non-static pages | Ryan Hübert |
| 8 | APIs | Ryan Hübert |
| 9 | Other data types | Ryan Hübert |
| 10 | Creating and managing databases | Ryan Hübert |
| 11 | Interacting with online databases | Ryan Hübert |
Detailed course schedule
Important note: Links to slides and code scripts will be updated/added in advance of each week’s teaching. There may also be minor adjustments/updates to the weekly readings posted below, so please monitor regularly.
1. Introduction
In the first week, we will introduce some basic concepts of how data is recorded and stored, and we will also review R fundamentals. Because the course relies fundamentally on GitHub, a collaborative code and data sharing platform, we will also discuss the use of git and GitHub.
Lecture
- Lecture
- Code: A plain R script, a first R markdown example, and a recap on vectors, lists, data frames
- Seminar
Seminar
- Review of Git/GitHub basics discussed in lecture
- Branches, merges, and pull requests
Readings
- Wickham, Hadley. Nd. Advanced R, 2nd ed. Ch 3, Names and values, Chapter 4, Vectors, and Chapter 5, Subsetting. (Ch. 2-3 of the print edition),
- GitHub Docs, especially: “About GitHub and Git”, “Hello World”, and “GitHub flow”.
- GitHub. “Basic formatting syntax” (a markdown cheatsheet).
- Markdown Guide. “Markdown Cheat Sheet.”
Additional readings
- Lake, P. and Crowther, P. 2013. Concise guide to databases: A Practical Introduction. London: Springer-Verlag. Chapter 1, Data, an Organizational Asset
- Nelson, Meghan. 2015. “An Intro to Git and GitHub for Beginners (Tutorial).”
- Jim McGlone, “Creating and Hosting a Personal Site on GitHub A step-by-step beginner’s guide to creating a personal website and blog using Jekyll and hosting it for free using GitHub Pages.”. (See also https://docs.github.com/en/pages/quickstart.)
2. Tabular data
This week discusses processing tabular data in R with functions from the tidyverse after some further review of R fundamentals.
Lecture
- Slides
- Code: Conditionals, loops, and functions, data processing in R, industrial production dataset, and industrial production and unemployment dataset
Seminar
- Code: Dplyr exercises, solution
Readings
- Wickham, Hadley and Garett Grolemund. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. Sebastopol, CA: O’Reilly. Part II Wrangle, Tibbles, Data Import, Tidy Data (Ch. 7-9 of the print edition).
- The Tidyverse collection of packages for R.
Note: there is a newer version of the Wickham and Grolemund text from 2023, which is available at https://r4ds.hadley.nz/.
3. Data visualisation
The lecture this week will offer an overview of the principles of exploratory data analysis through summarising data and (good) data visualisation. In the coding session and seminars, we will practice producing our own graphs using ggplot2.
Lecture
- Slides
- Lecture code: Anscombe quartet, ggplot2 walkthrough
- Data: Congressional Facebook posts, unemployment data
- Further reference code: ggplot2 basics, ggplot2 scales, axes, and legends
Seminar
- Code: Exercises in visualistion, solution
- Graphic to replicate: Unemployment rates
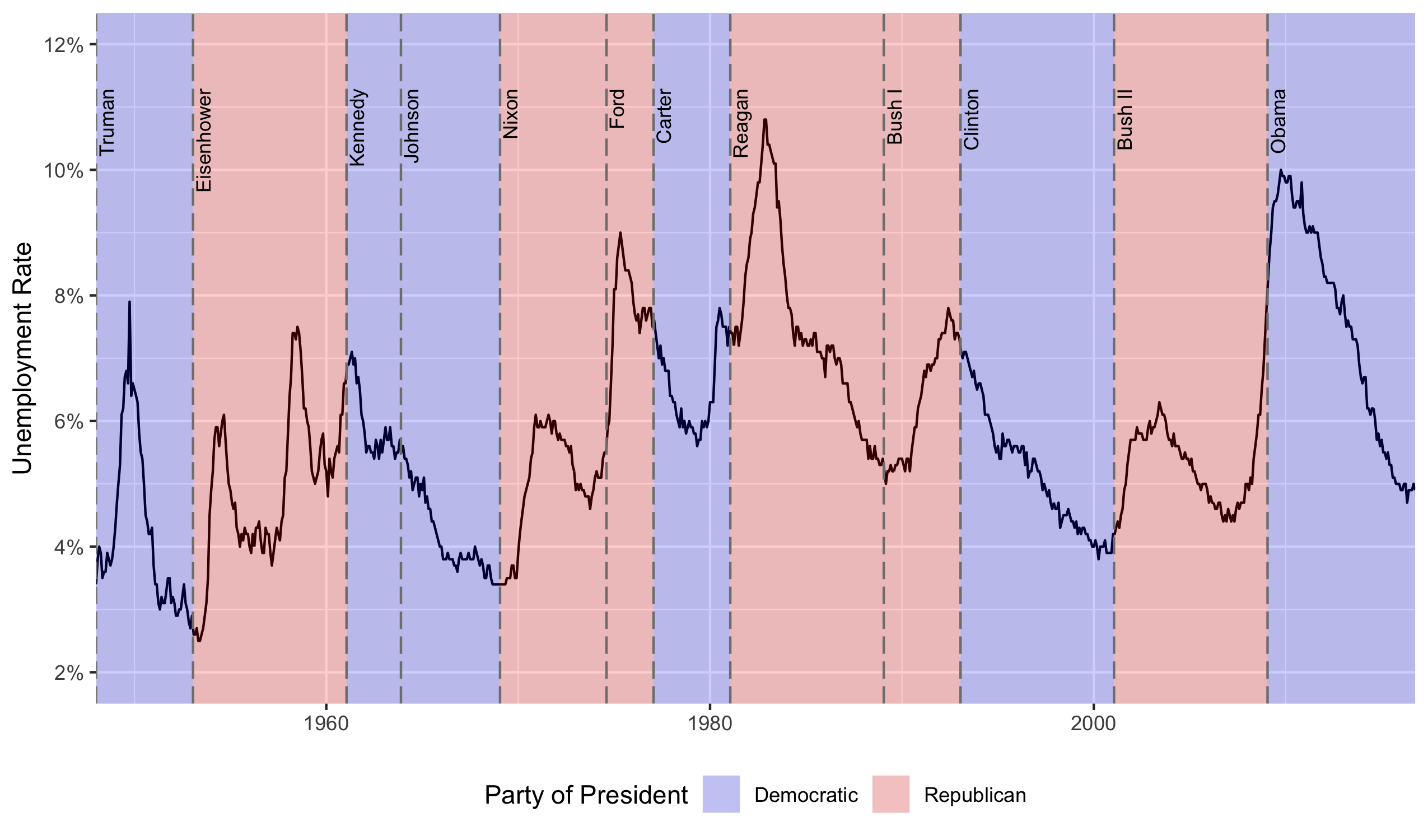{kind=link}
Reading
- Wickham, Hadley and Garett Grolemund. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. Sebastopol, CA: O’Reilly. Data visualization, Graphics for communication (Ch. 1 and 22 of the print edition).
Further reading
- Healy, Kieran. 2019. Data Visualization: A Practical Introduction. Princeton, NJ: Princeton University Press, ch. 1. Book available at https://socviz.co/.
- Hughes, A. (2015) “Visualizing inequality: How graphical emphasis shapes public opinion” Research and Politics.
- Tufte, E. (2002) “The visual display of quantitative information”.
- Wilkinson, Leland and Graham Wills. 2005. The Grammar of Graphics. 2nd ed. New York: Springer, 2005. Ch. 1. E-book available at LSE Library.
Formative problem set
This is a formative assessment, and is due 1 November 2024 by 5pm. You must submit your response as a knitted .html file via the Moodle page.
Feedback on the Practice Problem Set will be returned by 15th November (if submitted by the deadline).
More details to be made available later in the term.
4. Textual data
We will learn how to work with unstructured data in the form of text and discuss character encoding, search and replace with regular expressions, and elementary quantitative textual analysis.
Lecture
- Slides
- Code: Encoding and regex, text analysis, parsing pdfs
- Data:
Seminar
- Code: Exercises in text analysis, solution
- Data: news article, UoL institutions
Reading
- Kenneth Benoit. July 16, 2019. “Text as Data: An Overview” Forthcoming in Cuirini, Luigi and Robert Franzese, eds. Handbook of Research Methods in Political Science and International Relations. Thousand Oaks: Sage.
Further reading
- Wickham, Hadley and Garett Grolemund. 2017, Chapter 14
- Regular expressions cheat sheet
- Regular expressions in R vignette
5. HTML, CSS, and scraping static pages
This week we cover the basics of web scraping for tables and unstructured data from static pages. We will also discuss the client-server model.
Lecture
- Slides
- Examples: Website example 1, Website example 2, Website example 3, Website example 4, Website example 5
- Code: , selecting elements, scraping tables
Seminar
Reading
- Lazer, David, and Jason Radford. 2017. “Data Ex Machina: Introduction to Big Data.” Annual Review of Sociology 43(1): 19–39.
- Howe, Shay. 2015. Learn to Code HTML and CSS: Develop and Style Websites. New Riders. Chs 1-8.
- Kingl, Arvid. 2018. Web Scraping in R: rvest Tutorial.
Further reading
- Munzert, Simon, Christian Rubba, Peter Meissner, and Dominic Nyhuis D. 2014. Automated Data Collection with R: A Practical Guide to Web Scraping and Text Mining. Hoboken, NJ/Chichester, UK:Wiley & Sons. Ch. 2-4, 9.
- Severance, Charles Russell. 2015. Introduction to Networking: How the Internet Works. Charles Severance, 2015.
- Duckett, Jon. 2011. HTML and CSS: Design and Build Websites. New York: Wiley.
6. Reading week
Mid-term problem set
This is a summative assessment worth 50% of your final mark. It is due 22 November 2024 by 5pm. You must submit your response as a knitted .html file via the Moodle page.
Feedback on the Mid-term problem set will be returned as per the ASDS/SRM handbook.
More details to be made available later in the term.
7. XML, RSS, and scraping non-static pages
Continuing from the material covered in Week 5, we will learn the advanced topics in scraping the web. The topics include the scraping documents in XML (such as RSS), and scraping websites with non-static components with Selenium.
Lecture
Seminar
Reading
Further reading
- Mozilla Developer Web Docs. What is JavaScript.
- Web Scraping with R and PhantomJS.
- Mozilla Developer Web Docs. A First Splash into JavaScript.
8. APIs
This week discusses how to work with Application Programming Interfaces (APIs) that offer developers and researchers access to data in a structured format.
Lecture
- Slides
- Code: JSON in R, AIC API
- Data: example_1.json, example_2.json, example_3.json
- Extra example: Google Maps API
Seminar
Reading
- Barberá & Steinert-Threlkeld. 2018. “How to use social media data for political science research”. In The Sage handbook of research methods in political science and international relations, pages 404-423.
Further reading
- Ruths and Pfeffer. 2014. Social media for large studies of behavior. Science.
9. Other data types
We will learn how to work with other data types, including audio, visual and spatial data.
Lecture
Seminar
- Code: 03-MPs.Rmd, 03-MPs-solution.Rmd
Reading
- Araya-Salas, Marcelo. 2023. Bioacoustic Analysis in R: Organization for Tropical Studies. https://marce10.github.io/OTS_BIR_2023/, tutorials on sound, spectrograms and
seewave. - Geocomputation with R. https://r.geocompx.org/, ch. 2.
- Zhang, Zhiyong. 2019. Practical Data Processing for Social and Behavioral Research Using R. https://books.psychstat.org/rdata/index.html, chs. 5 and 6.
Further reading
- Cantú, Francisco. 2019. “The Fingerprints of Fraud: Evidence from Mexico’s 1988 Presidential Election.” American Political Science Review 113(3): 710-726. https://www.cambridge.org/core/journals/american-political-science-review/article/fingerprints-of-fraud-evidence-from-mexicos-1988-presidential-election/8F3C1BCA4C53FE85EA48E51321E339E9
- Geocomputation with R. https://r.geocompx.org/, all chapters.
- QGIS. “8. Coordinate Reference Systems.” in A Gentle Introduction to GIS. https://docs.qgis.org/3.34/en/docs/gentle_gis_introduction/coordinate_reference_systems.html
sfdocumentation- Sonos. “Mono vs. Stereo Sound: What’s the Difference?” https://www.sonos.com/en-gb/blog/mono-vs-stereo-sound
10. Creating and managing databases
This session will offer an introduction to relational databases: structure, logic, and main types. We will learn how to write SQL code, a language designed to query this type of databases that is currently employed by many companies; and how to use it from R using the DBI package.
Lecture
Seminar
- Code: SQL exercises, solution
Reading
- Beaulieu. 2009. Learning SQL. O’Reilly. (Chapters 1, 3, 4, 5, 8)
Further reading
- Stephens et al. 2009. Teach yourself SQL in one hour a day. Sam’s Publishing.
11. NoSQL and cloud databases
This week covers how to set up and use relational databases in the cloud and fundamentals of a document based NoSQL database.
Lecture
Seminar
Required
- Beaulieu. 2009. Learning SQL. O’Reilly. (Chapters 2)
- Hows, Membrey, and Plugge. 2014. MongoDB Basics. Apress. (Chapter 1)
- Tigani and Naidu. 2017. Google BigQuery Analytics. Weily. (Chapters 1-3)
Further reading
Final take-home assessment
This is a summative assessment worth 50% of your final mark. It is due Wednesday, 15 January 2025 by 5pm.
More details to be made available later in the term.